
外文翻译 | FlyMC:高度可扩展地测试分布式系统中的复杂交错
作者:Jeffrey F. Lukman, Huan Ke, Cesar A. Stuardo等
日期:2019年3月25日
原文链接:
https://ucare.cs.uchicago.edu/pdf/eurosys19-flyMC.pdf
摘要
我们为数据中心/云系统提供了一种快速且可扩展的测试方法,例如Cassandra,Hadoop,Spark和ZooKeeper。这个方法的独特之处在于它有能力可以通过复杂的消息交错来测试工作负载,以克服路径/状态空间爆炸问题故障。我们介绍了三种强大的算法:状态对称性,事件独立性和并行翻转。相对于其他最新解决方案,这些算法都使我们的方法比平均速度快16倍(最高78倍)。我们将技术与8种广泛使用的数据中心系统集成在一起,成功重现了12个旧缺陷,并发现10个新缺陷。这些均在没有随机游走或手动检查点的情况下完成。
CCS概念•计算机系统组织→云计算;分布式体系结构 ; 可靠且容错的系统和网络 ; 可靠性。
关键字:可靠性,可用性,分布式系统,软件模型检查,分布式并发错误
引言
数据中心系统,例如分布式Key-Value Store,可扩展的文件系统,数据并行计算框架以及分布式同步服务,是现代云的骨干引擎。但它们是复杂的。这个复杂性使它们很难正确使用。在此类系统中的所有类型的问题中,复杂的消息交错,崩溃,重新启动是最麻烦的问题[39, 50,61,62,79]。跨多个节点的事件的这种不确定性顺序会导致“分布式并发”错误出现(或简称为“ DC错误”)。开发人员每月处理DC问题[45,48],或更糟糕的是每周处理新开发的协议[6]。它们难以复现和诊断(要花费数周到数月的时间才能修复大多数问题),并导致有害后果,例如整个集群不可用,数据丢失/不一致以及操作失败[59]。
理想情况下,应该在测试中发现错误,而不是在部署中发现错误[35]。一种符合要求的系统测试技术是无状态/软件模型检查。该检查直接在实施级别的分布式系统上运行[46,49,55,58,73、80、81]。这些软件模型检查器1尝试对不确定性事件进行许多可能的交错,例如消息和故障时机,从而将目标系统推向未探测状态,并可能揭示难以发现的错误。
检查器1在本文中,“检查器”专门代表了分布式系统的软件模型检查器,不包括“本地”线程调度检查器[22、66]或经典模型检查器[37、42]。

图1. 检查器1可扩展性
x轴代表经过测试的协议(Raft或Paxos),并具有1到3个并发更新。对数比例的y轴表示耗尽搜索空间的路径数(即路径爆炸)。与我们的检查器FlyMC相比,当前的检查器在更复杂的工作负载下无法很好地扩展。“↑”表示路径探索不完整
检查器的克星之一是路径爆炸问题。举例说明,假设有10个并发消息(事件){a,b,..,j},那么诸如深度优先搜索(DFS)之类的简单检查器必须执行10!个(阶乘)特定执行路径(ab..ij,ab..ji等)。图1进一步说明了爆炸问题。灰色的“ DFS”栏显示了在简单工作负载下(例如Raft更新协议(“ Raft-1”)的实例化)[67] 几乎有100条路径(沿y轴)探索。
为了解决这个问题,检查器采用了路径缩减算法。例如,MODIST [81]和其他一些人[73,80]修改了流行的动态局部降阶(DPOR)概念[38,41],“由给定节点处理的消息独立于发往其他节点的其他并发消息(因此,不需要交错)。” SAMC [58]也进一步扩展了DPOR。结果相较原始DFS方法的路径减少效果显著,如图1中的Raft-1的“ mDPOR”和“ SAMC”栏所示。
尽管取得了这些早期的成功,但我们发现在更复杂的工作负载下,路径爆炸问题仍然没有得到解决。例如,在两个或三个并发的Raft更新(图1中的Raft-2和-3工作负载)下,在MODIST和SAMC中探索路径的数量仍然显著增加。更不用说更复杂的工作负载,例如Paxos [57],路径爆炸更大(例如,图1中的Paxos-1到-3工作负载)。

图2. Cassandra Paxos(CASS-1)中的复杂DC错误
我们将此错误标记为“ CASS-1” [4],该漏洞需要进行三个Paxos更新,并且仅需要两次翻转就可以暴露(在提议以投票1提交之前必须启用带投票2的prepare消息,在提议投票2之前必须启用带投票3的prepare消息)发生在54个事件的所有可能翻转中,导致数据不一致
综上所述,现有检查器无法在更复杂的分布式工作负载下扩展。但是实际上,一些现实世界中的错误仍然隐藏在复杂的交错之后(第7节)。例如,图2中Cassandra中的Paxos错误只能在具有三个并发更新和总共54个事件的工作负载下出现。使用现有的检查器这些类型的错误将需要数周的时间出现,浪费了测试计算资源,延迟了错误的发现和修复。由于上述所有原因,为了找到DC错误,一些检查器将其算法与随机游走[81]或手动检查点[49]混合在一起,希望更快地达到导致DC错误的“有趣的”的交错。但是,这种方法变得不系统。与系统地覆盖和可观察事件有关的所有状态覆盖率相比,随机和手动方法导致的覆盖范围较差。
我们介绍FLYMC,这是一种快速,可扩展且系统的软件/无状态模型检查器。它涵盖了与可观察事件有关的所有状态,以测试分布式系统的实现。FLYMC通过利用分布式系统的内部属性来实现可扩展性。
我们在下面用三种FLYMC的算法进行说明。
(1)通信与状态对称:在云系统中很常见,许多节点具有相同的角色(例如,跟随者节点,数据节点)。这种对称节点的状态转换通常仅取决于消息的顺序和内容,而与节点ID /地址无关。因此,FLYMC减少了代表相同对称通信或状态转换的不同路径为单条路径。
(2)事件独立性:尽管状态对称性大大省略了对称路径,但许多事件仍必须在非对称路径中进行排列。FLYMC能够识别大量事件独立性,可以利用这些事件独立性来减轻浪费的重新排序。例如,FLYMC自动将更新不相交变量集的并发消息标记为独立。FLYMC还可以在与系统崩溃相关的事件之间找到独立性。
(3)平行翻转:尽管先前的方法减少了对每个节点的消息交错,但是总的来说,仍然必须在所有节点之间完成许多翻转(事件的重新排序)。问题在于,在现有的检查器中,一次仅翻转(重新排序)一对事件。为了加快速度,并行翻转在不同节点上同时执行并发消息的重新排序,以快速达到难以到达的极端情况。
最后,不仅路径减少而且wall-clock(现实时间)速度也很重要。为了某些正确性和功能目的,现有的检查程序必须在每对启用的事件之间等待不可忽略的时间。在简单的工作负载下,等待时间是合理的,但会严重影响复杂工作负载的总测试时间。FLYMC通过执行本地顺序和状态转换缓存来优化此设计,这将在后面进行介绍(第5节)。
总的来说,这些算法使FLYMC平均比其他先进的基于系统和随机的方法快16倍(最高78倍),并且设计优化将其提高到28倍(最高158倍)。FLYMC与8个广泛使用的系统集成在一起,这是我们所知道的最大数量的集成。我们对10个协议实现(Paxos,Raft等)进行了模型检查,成功重现了12个旧错误,并发现了10个新的DC错误,这些错误均已被开发人员确认,并且均以系统的方式进行,没有随机游走或手动检查点。这些错误中的某些错误是在合理的时间内无法由先前的检查器解决的。我们有公开发布了FLYMC [20]。
以下各节详细介绍了我们的四个贡献:
1. 高度可扩展的检查器算法,可为给定的工作负载提供系统的状态覆盖。(第3节)。
2. 支持静态分析的检查器设计可帮助开发人员从目标系统中提取信息,并使用其编写算法的特定部分(第4节)。
3. 其他改进功能可改善检查程序的探索路径中的wall-clock速度(第5节)。
4. 与具有挑战性的应用程序进行了全面的集成,并通过详细的评估证明了检查程序的有效性。(第6-7节)。
对于有兴趣的读者,我们提供了深入的技术报告[21]。
背景
Checker架构:检验器的概念及其详细工作原理可以在现有检验器文献中找到[58,第2.1节] [81,第2节] [73,第3节] [21,第2节]。本节简要讨论了重要的组件和术语。
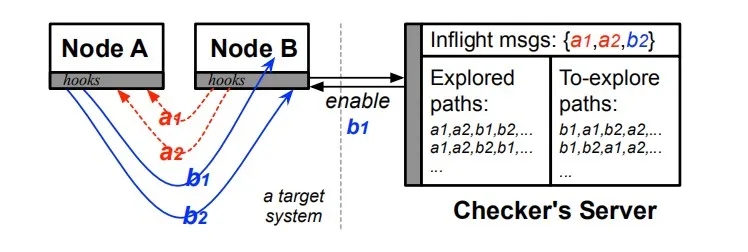
图3.检查器架构
如图3所示,检查器运行目标工作负载(例如,在节点A和B中)并拦截所有运行中的消息(例如,被灰色“钩子”拦截的并发消息a1,a2,b1和b2)以控制其时间。然后,检查程序的服务器一次启用一个消息事件(例如,启用b1)。检查程序的钩子等待目标系统停止运行(在处理b1之后),节点等待将新的结果全局状态(例如S1)传递给检查程序的服务器,该服务器将其记录为状态事件历史记录(例如S0 + b1) →S1)。开发人员决定要检查的全局状态变量(例如,角色,领导者,投票编号)。然后,服务器运行断言以查找新状态下的任何安全冲突。
每个启用事件生成的新事件将被检查器再次拦截(例如,响应b1生成的a3,图中未显示)。整个过程重复执行(S0 + b1→S1,S1 + b2→S2,... + a3→...),直到到达终止点——违反规范或工作负载无任何违反地终止(例如,没有观察到更多消息)。这形成了一条探索路径(例如b1b2 ... a3)。路径表示事件的唯一总顺序;它也被称为“跟踪”或“执行序列” [44、54、81]。
给定先前使用的路径,检查器将置换可能的交错(以探索路径)并重新启动工作负载。例如,在下一次运行中,它将在b1之前翻转b2,因此在相同的工作量内使用新的路径b2b1...。路径也可以包含崩溃/重启事件;例如,路径b1BB↑b2 ...表示在处理b1之后,但在b2到达之前注入了崩溃B和节点B上的重新启动B↑。如果存在,则整个测试完成(耗尽状态空间) 没有更多的探索途径。
FLYMC算法
通过考虑分布式系统的属性,我们使FLYMC具有两种简化算法:通信和状态对称(第3.1节)和事件独立性(第3.2节);一种优化算法:并行翻转(第3.3节)。这两种简化算法减少了不必要的交错(冗余路径),这些交错会导致探索之前相同的状态。优化算法对交错进行优先级排序,从而可以更快地处理极端情况。
在本节中,我们以以下格式描述每种算法:
(a)要解决的特定路径爆炸问题;
(b)减少或确定优先级的直觉;
(c)高层描述中的算法;
(d)与现有解决方案的比较。
在第4节的后面,我们将讨论正确实现这些算法的复杂性,以及我们的静态分析支持如何在这方面帮助开发人员。
通信与状态对称
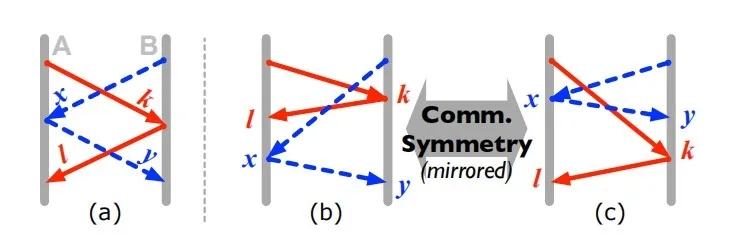
图4.通信对称性
解释图在第3.1节的部分问题
难题:让我们想象一下图4a中的简单通信,其中消息k triggersl,x触发器y,k和x是相同类型的消息(例如,写请求)。图4b和4c示出了两个可能的重新排序的路径klxy和xykl。尽管这些路径似乎不同,但它们在图4b-c中的通信结构暗示了不对称减小的可能性。
在本地并发文献中实现对称约简的一种方法是抽象系统属性[32,33,75]。将其应用于分布式系统时,我们最初尝试仅抽象通信结构,特别是通过将发送方和目标节点ID(例如IP地址)抽象为规范的接收顺序;例如,在图4b中,由于节点B是第一个接收到的节点,因此其节点ID被抽象为节点“ 1”(例如,kA→B变为k2→1)。类似地,在图4c中,由于节点A是第一个接收到的节点,因此它的节点ID被抽象为节点“ 1”(例如,xB→A变为x2→1),因此,由于k和x是消息,因此这两个图表现出通信对称性。从节点“ 2”到“ 1”具有相同类型。
不幸的是,这种方法并不总是有效的,因为大多数消息都带有唯一的内容。例如,在Paxos中,消息k和x带有不同的投票号,因此不能被相同地对待。因此,尽管图4b和4c中的通信结构(箭头)看起来是对称的,但仅对消息进行抽象并不会导致大量减少。
简介:幸运的是,在许多云系统中,许多节点具有相同的角色(例如,跟随者节点,数据节点),尽管它们的节点ID不同。此外,这种对称节点的状态转换通常仅取决于消息的顺序和内容,而与发送/接收节点ID无关。
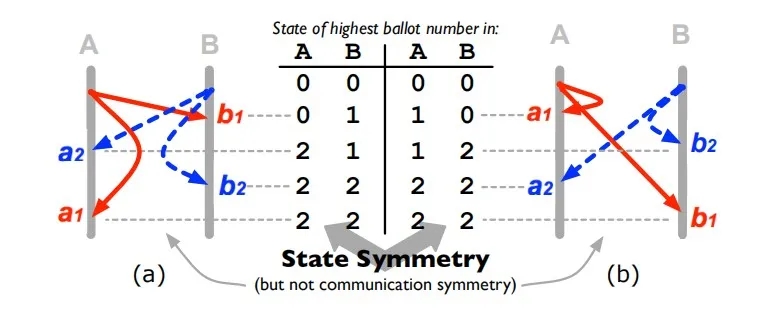
图5.状态对称
该图在第3.1节的“直觉”部分中进行了说明
为了说明这一点,让我们考虑图5a-b中的两个通信结构,它们代表了具有两个并发更新(实线和虚线)的(大大简化了)Paxos实现的第一阶段。节点A广播其准备消息(实线),a1向其自身广播,b1向节点B广播,“ 1”表示投票号1。类似,节点B向其自身广播b2,广播给投票号2的节点a2(虚线) 行。
如果我们比较图5a-b中的两个通信结构,则它们不是对称的,这与图4中的先前示例不同。但是,让我们分析每个节点的状态转换,例如该节点已收到的最高投票数,如图3所示。图5的中间表。在此Paxos示例中,每个节点仅接受较高的选票,而放弃新的较低的选票,因此节点的准备状态单调增加。按照图5a中的b1a2b2a1的左顺序,节点A的状态转换为00222,而节点B的状态转换为01122。右边的顺序a1b2a2b1,状态转换是对称的(镜像),A中为01122,B中为00222。
综上所述,尽管两条路径没有显示出通信对称性(图5a-b),但它们的状态转换却是对称的(中间表)。因此,状态对称对于路径修剪可能是有效的(例如,如果已经探索过b1a2b2a1,则a1b2a2b1就是多余的)。
算法:为实现对称性,首先,我们保留过去执行过的状态-事件转换(第2节)的历史记录,格式如下:Si + ej→Sj其中“ S”表示全局状态(即, 每个节点状态的集合)和ej是下一个启用的事件。因此,启用ej时,全局状态将从状态Si转换为Sj。
此外,我们保留了{absState + absEv}过渡的历史记录,其中absState表示抽象的全局状态(按字母顺序),不包括对称节点(如数据节点)的节点ID(以及类似的absEv forevents)。使用图5a中的示例,第一个事件将生成{00 + 1},其中00表示数据节点A和B的抽象状态(仅具有最高的投票号,不包括节点ID),而1表示抽象的a1消息。随后,我们将{01 + 2},{12 + 2}和{22 + 1}记录到历史记录中。重要的是要注意状态12来自字母顺序的状态21;也就是说,对称实现需要按字母/数字排序。
根据这个历史记录,图5b中的第二阶a1b2a2b1将被标记为对称;当系统处于状态00时启用a1(抽象为+1)时,将找到历史匹配项{00 + 1}。同样,对于b2(抽象为+2),当系统处于状态01时,将找到匹配项{01 + 2}。一个警告是,由于仍在建立历史记录,因此状态对称在较早的路径中效果较差,但是在经过一些初始路径后,“缓存命中率”显着增加(第5节中有更多说明)。
比较:在经典(状态)模型检查中,对称性通常用于对称处理器[32,75]。在分布式检查器中,除了SAMC[58],没有发现使用对称性的方法[46,49,55,58,73,80,81]。但是,SAMC仅使用对称性来减少不必要的崩溃时间,而没有用于并发消息。FLYMC的对称性更为强大,因为它还可以概括碰撞时间。更具体地说,崩溃是作为针对特定节点的崩溃事件而抽象的。例如{12 +2}意味着在节点上注入了编号为2的崩溃(与数据节点ID无关)。
事件独立性
难题:尽管状态对称性省略了对称路径,但在非对称路径中,还有许多其他事件需要重新排序。例如,如果四个不同类型的消息a1 ... a4与节点A并发,则排列将导致4!倍多的路径。由于仍然必须对发送给每个节点的一些并发消息进行重新排序,因此需要进行更多的减少。

图6.具有多个崩溃的复杂计时的ZooKeeper错误(ZOOK-1)
该错误在第3.2节和第7.1节中被引用。标记为ZOOK-1 [13]的错误需要46个事件,包括3个崩溃事件和3个重新启动事件,以及两个传入事务,ZooKeeper原子广播(ZAB)和领导者选举(LE)协议之间的复杂并发

直觉:在这种情况下,FLYMC适应了引言中提到的DPOR的“独立”(又称可交换性)概念。在DPOR中,如果Si + e1 + e2→Sj和Si + e2+ e1→Sj,则两个事件e1和e2是独立的。也就是说,如果e1e2或e2e1导致了从Si到Sj的相同全局状态转换,则当系统位于Si时,事件对e1和e2不必翻转,从而减少了探索路径的数量。分布式系统中独立性的一个示例是,当许多并发消息(到达目标节点)更新不同的变量时。例如,在某些分布式系统(例如ZooKeeper)中,原子广播协议可能与领导者选举协议同时运行(由于节点崩溃),但是这两个协议中的某些消息不会更新相同的变量(当系统处于特定状态Si),因此没有必要翻转它们。
算法:尽管有状态模型检查器(具有已知的状态转换)[29,38,41,69]提出了DPOR /独立性的概念,但使其适应无状态分布式检查器并不是一件容易的事–检查器如何事先知道Si + e1e2和+e2e1在执行事件之前会导致相同的未来状态Sj吗?为此,FLYMC通过静态分析帮助开发人员提前识别不相干的更新(第4.1节中的更多详细信息)。
本质上,对于发送给节点N的每条消息ni,我们的静态分析都会在n当前状态下处理ni的流程中,构建实时readSet和updateSet,这是一组待读取和已更新的变量。也就是说,我们的方法结合了以下事实:ni的读取和更新集会随着节点N在不同状态之间的转换而改变。因此,如果ni的readSet和updateSet在当前状态Si下不与nj的updateSet重叠,则发给节点N的两条消息ni和nj被标记为独立,反之亦然。此外,如果两个消息的updateSets完全相交,并且集合中的所有变量都增加/减少了一个(例如,分布式系统中的通用确认增量“ ack ++”),然后将这两个消息标记为独立/可交换。
除了减少不必要的消息交错之外,可伸缩检查器还必须减少在不同时间的不必要的崩溃注入。50%的DC bug只能在至少一个碰撞注入后浮出水面,而12%的DC bug在特定时间至少需要两次碰撞事件[59](例如,图6中复杂的ZooKeeperbug),这进一步加剧了路径爆炸问题(设想不同) 故障定时,例如..a1a2A..,..a1A..,..a2A..,其中“A”表示节点A崩溃)。因此,FLYMC的独立性适应性的另一个独特之处是为碰撞事件构建了以上场景。例如,如果跟随者节点崩溃(B),而领导者节点A通过减少活动节点数(例如liveNodes–)作出反应,则B的updateSet将包含A的liveNodes变量。
比较:先前的检查程序采用了DPOR的独立性,但程度有限,因此在复杂的交错下无法扩展。例如,MODIST [81,第3.6节],CrystalBall [80,第2.2节]和dBug [73,第2节]仅采用DPOR,其规则如下:“给定节点要处理的消息独立于其他并发消息 运往其他节点”。但是,因为它们是不分析目标源代码的黑匣子检查器,所以他们找不到更多的独立性。另一方面,FLYMC是白盒检查程序,它在当今基于DevOps的云开发中利用对源代码的访问,开发人员是测试人员,反之亦然[60]。
SAMC是白盒检查器的另一个示例,但是开发人员需要手动分析其目标系统代码并遵循SAMC简单原则。因此,SAMC仅引入了谨慎而严格的归约算法,这些算法的功能不如FLYMC强大(请注意,在FLYMC中,上述集合的内容将通过静态分析支持自动构建)。
例如,FLYMC将丢弃的消息([58,第3.3.1节])概括为空的updateSet,这样的消息将自动与任何其他消息不冲突,因此不需要重新排序。再举一个例子,不会导致新消息的崩溃(例如,跟随节点B崩溃后仍保持仲裁)将不会与所有未完成的消息交错[58,第3.3.2节],因为FLYMC自动识别崩溃事件B的updateSet(例如,领导节点中的liveNodes)与运行中消息的updateSet不冲突。
平行翻转
难题:虽然我们以前的方法减少了对每个节点的消息重新排序,但总的来说,仍然必须在所有节点之间进行许多翻转。问题在于,在现有的检查器中,要创建新的重新排序路径,一次只能翻转一对事件。例如,在图7a中,两个并发消息a1和a2正在传输到节点A,四个消息b1 ... b4则传输到节点B。图7b说明了现有方法如何一次仅翻转一对非独立事件;例如,在路径#1 a1a2b1b2b3b4之后,通过在b3之前滑动b4,然后在b2之前滑动b4的后继路径#3,创建下一个路径#2,依此类推。现在,让我们假设一个错误是由a2a1排序引起的(即,必须在a1之前启用a2)。在上面的标准方法中,将花费4!重新排序(到B的四个消息中),然后才有机会在a1之前翻转a2。
直觉:在分析BUG基准时,我们观察到了这样的规律。例如,要中了图2中的Paxos bug,nodeC必须在Commit#1之前接收到Prepare#2消息,但有8个更早的in-flight消息到其他节点,必须重新排序。更糟糕的是,在这之后,Prepare#3消息必须在Propose#2之前到达,但有5个更早的消息需要翻转。因此,诱发BUG的翻转没有提前行使。
这个问题促使我们引入平行翻转。也就是说,我们允许对事件的平行翻转,而不是一次翻转一次,而是允许对事件的并行翻转。并行翻转也符合一个典型的开发者的观点,即成熟的云系统一般在 "一阶"(常见交错下)都是稳健的,但同时在所有节点上进行 "不常见 "的交错,可能会更快地发现bug[27]。
算法:对于下一个要探索的路径,我们在每个节点中翻转两个消息对,因此在所有N个节点中同时翻转N次(但我们不在一个节点内进行多次翻转)。例如,在图7c中,在执行路径#1 a1a2b1...b4后,在路径#2中,我们同时进行了a2a1和b4b3的翻转。这是允许的,因为在飞行过程中向节点A发送的信息与向节点B发送的信息是独立的(根据我们的DPOR 在§3.2中采用)。如果无法进行平行翻转,则返回到单次翻转(例如,在路径#3中只进行b4b2翻转)。
我们强调,并行翻转是一种优先级算法,而不是简化算法。也就是说,这种算法可以帮助开发者更快地挖掘出bug,但不会减少状态空间。因此,在实现中,FLYMC保留了并行翻转之前的单次翻转路径,并将并行翻转之前的单次翻转路径转化为一组低优先级的探索路径,这样FLYMC就可以保持系统性。
比较:我们没有发现有任何分布式检查器采用并行翻转这样的算法。然而,在软件测试文献[31,44]中,我们发现,我们的方法在精神上类似于 "分支翻转",即同时翻转多个分支约束,以更快地覆盖更多的极端案例。
智联联盟秘书处翻译,如有需调整、需提高等,欢迎反馈!